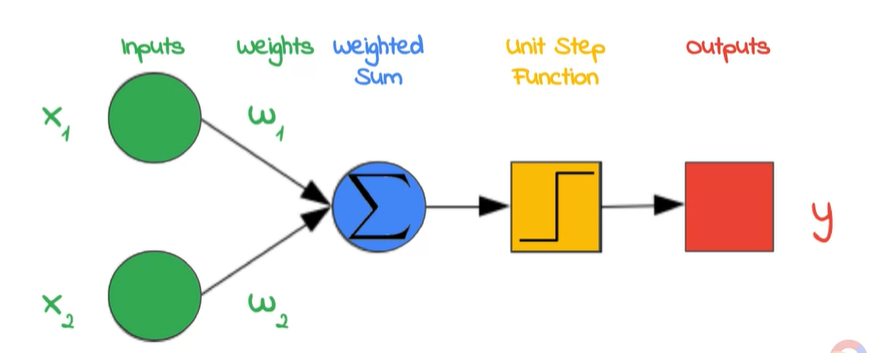
今天來聊聊關於ML發展的整個流程吧,在1800s人類提出線性回歸的觀念,在1940s科學家開始希望電腦可以效仿人類做事情,第一個被提出來的就是Perceptron(感知器),它是仿造人體腦袋內的神經元進行動作,依照人類看神經元的角度來說其中基礎架構包含細胞核 (nucleus)、樹突 (dendrites)和軸突 (axon)、髓鞘(myelin sheath)。
但以數學或是工程的角度來看它就是一個有輸出與輸入中間透過數學運算產生的結果如下圖。
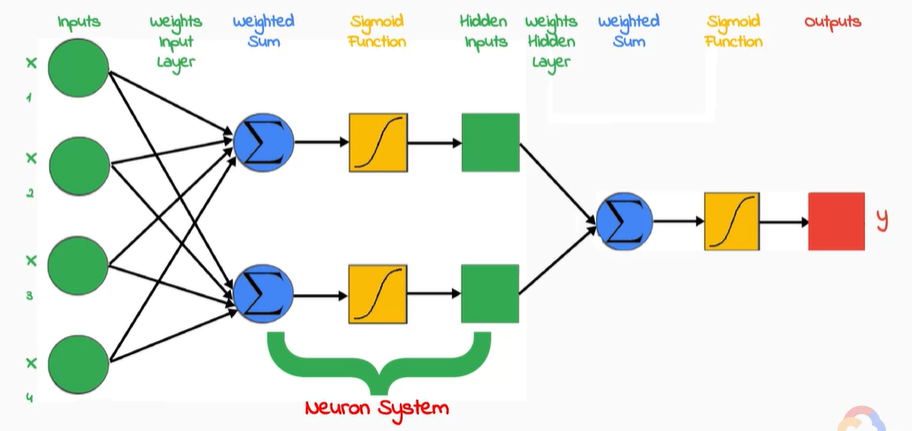
接著馬上有人提出組合上述感知器把它變成一個大網路是不是可行的,就像下圖將多個感知器組合起來建構出一套系統,並且其中使用所需的激活函數來達到我最後輸出的結果,例如tanh、sigmoid、relu 函數都是大家常使用的激活函數詳細的數學式,這邊就不詳細做說明,有興趣的朋友我給予一個網站給大家做參考。
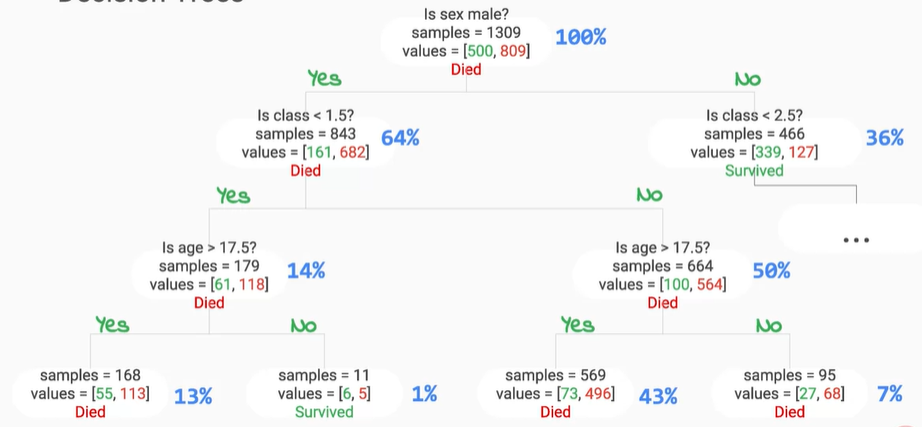
接著介紹Decision Trees決策樹的部分,決策樹就像一棵樹會使用二分法不斷做分支,直到確定所有樣本都被分完,樹就停止成長,所以在分裂的過程中會有多種條件來做分類,像是想要知道一個族群中男女生裡面有無近視並且年紀大於20歲然後收入大於22k的人有哪些?這個問題就很適合利用決策樹模型來進行分類。
之後有人提出Kernel Methods,最著名的就是支援向量機SVM,簡單來說就是在分類過後加了一些margin,給予我的模型一些寬容,藉此能更加擬合所有數據。若是資料看起來不好分辨,也能轉換至多維空間使得結果表現如同平面。
而這部分詳細的數學推導公式與相關知識,推薦台大林軒田老師的課程,老師講得非常詳細。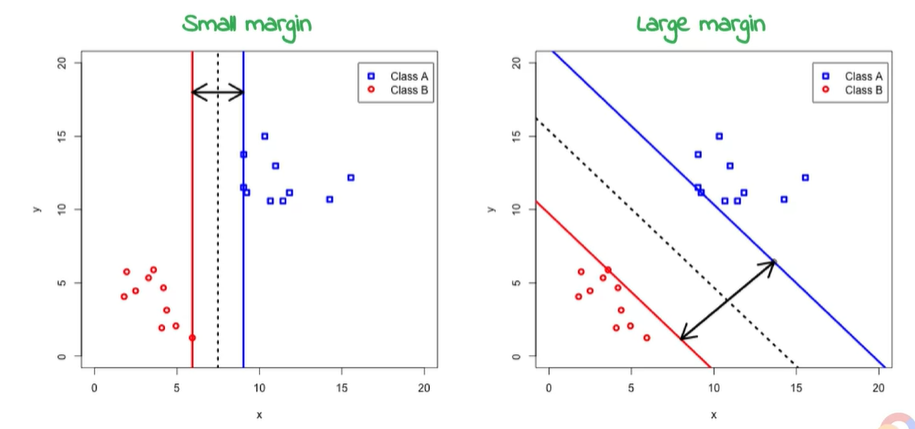
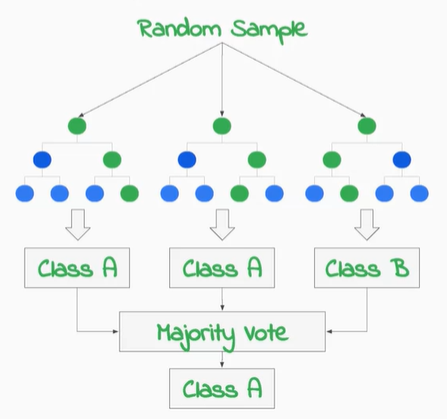
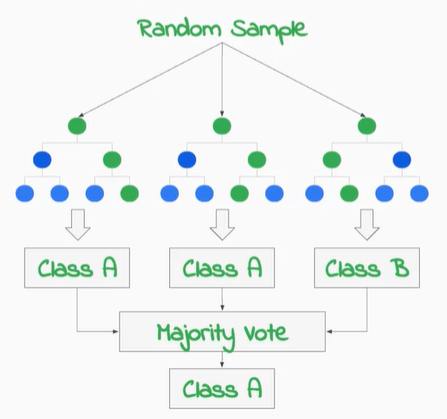
而Random Forests隨機森林的部分,大家可以把它想成好幾顆決策樹的集合,沿用上面的例子,假設今天族群很多,有可能來自台北、台中、高雄、花蓮…等地點,那我想知道全台灣男女生裡面有無近視並且年紀大於20歲然後收入大於22k的人有哪些?這個狀況下我們就可以採用隨機森林的方式,在最後使用多數決的方式來找出到底哪個地方是符合我要的條件。
而到現今這個階段,大多數人採用Neural Networks的概念,但現在多了很多種類去做延伸的動作,很多人都會講到DNN、RNN、CNN,其實這些都是Neural Networks的延伸,當然大家就可以利用這些方法去建構自己的神經網路,像是Google也發展出他們自己的神經網路來進行圖像的辨識,最有名的就是GoogleNet,除了給了大家一個建構模型的標準,想要進行圖像辨識的人也能直接使用pretrain後的model來做使用,大大減少訓練時間以及資料的蒐集,對所有圖像領域的研究是一大福音呀!
※圖片參考至 Launching into Machine Learning slide